“青春期”的深度學習:現狀與未來展望

4月16-17日,【2021全球機器學習技術大會】在北京盛大舉辦。谷歌大腦高級研究科學家Lukasz Kaiser 作為 keynote 演講嘉賓,分享了《Deep Learning Adolescence : What's Great and What's Next》的專題演講。以下為演講內容。

全球機器學習技術大會 Lukasz演講現場照
雖然如今深度學習已經取得了很多進展,但是我感覺深度學習仍然處在青春期階段,所以今天想跟大家討論一下未來我們能夠有哪些進展?
2016年是深度學習的一個重要節點,對于NLP的發展也是一個重要里程碑。谷歌很多人已經對一些任務進行研究,有20年甚至更長的時間,比如:磁性標記,即興創建,命名實體識別,語言建模,翻譯,句子壓縮,抽象性總結,問題解答等。每個在研究系統里的人,都需要做大量的編碼,在翻譯上任務就更加復雜。
在深度學習領域,如果想把英文翻譯成中文,首先需要輸入一些變量,才會有輸出變量,而這些變量都是大小可變的,神經網絡將如何處理這些數據?以前是用NLP來處理這個問題,但實際效果并不是很好,而在編碼和譯碼,也就是涉及到序列的處理方面,最終效果和原來相差不多。
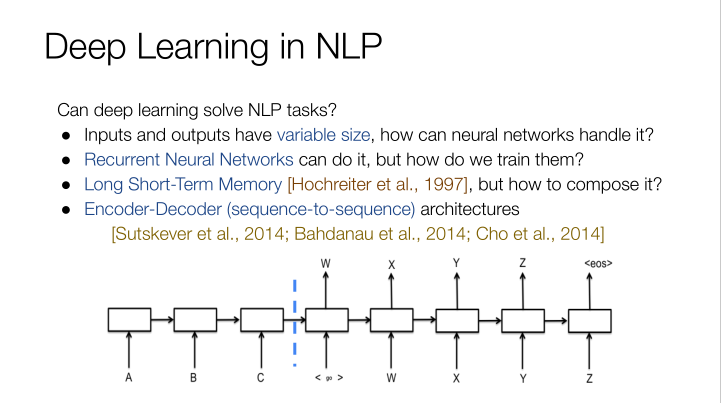
我們前面談到的幾大NLP任務,都可以通過地硅神經網絡LNN來進行解決,聽起來很簡單,現實會更加復雜。在LSTMs模型上面,我們有不同的GPU層,每一層的工作效率都基于上一層的結果,我們的問題就是這些深度的LSTMs模型它行得通嗎?答案是大部分時候可以做到。
我們以困惑度來衡量語言模型的性能,困惑度越低越好。通過不同的模型,我們將困惑度從67.6慢慢降低到28。

以語言模型示例:
英文:Yuri Zhirkov was in attendance at the Stamford Bridge at the start of the secondhalf but neither Drogba nor Malouda was able to push on through the Barcelonadefence .
中文:下半場初由禮什爾科夫出席了斯坦福比賽,但德羅巴和馬羅達都無法通過巴塞羅那的防守。
從英文來講,語句是非常通順的。計算機能識別出這里有3個人的名字,他們都是足球運動員的名字,再加上前面的單詞和短句,計算機推算出下一個單詞和未來句子的走向。很多模型能夠實現這樣的效果,那么在翻譯上行得通嗎?
翻譯的性能是以BLEU的分數來衡量的,分數越高越好。以短句為基礎的機器學習,BLEU分數是12.7;早期的LSTM模型,分數是19.4,大型的LSTM模型(谷歌目前正在用的模型),它的分數是20.6;更大的GNMT的LSTM模型分數是24.9。BLEU分數只是一個打分標準,實際情況下翻譯的效率和準確度如何呢?
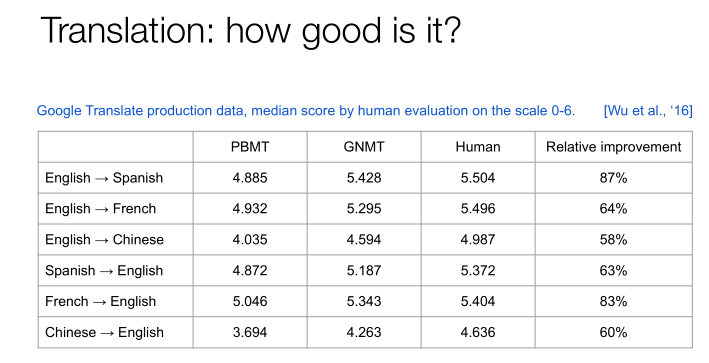
我們讓很多人來讀了一下這些翻譯的文本,可以看到PBMT的分數是4.885,GNMT的分數是5.428,人類能達到的分數是5.504。不管是從英文到不同語種,還是不同語種之間的翻譯,可以得出非常一致的結論就是,機器翻譯方面我們已經取得了非常大的進展。
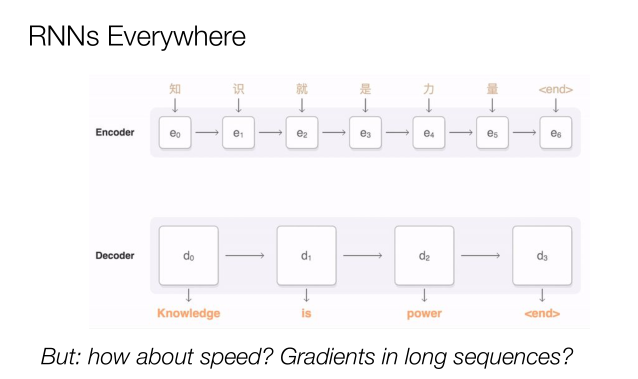
那未來會出現什么問題?機器翻譯以短語為基礎,而人們通常傾向于將整篇文章進行翻譯。這時RNN神經網絡非常重要,因為它無處不在,我們可以先編碼再譯碼,但是當序列越來越長的時候問題就出現了,整個文本量非常大話問題就會更多,所以重點是我們如何能夠在目前的狀況下保有它的性能?如何能夠提升它的速度,并且在長序列中進行漸變?
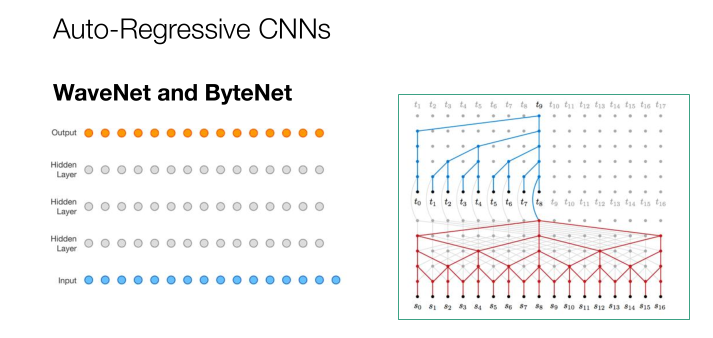
2017年,這個時候自回歸的CNN展現了更多的能力。從輸入層到幾個隱藏層再到輸出層,這是WaveNet and ByteNet的工作模式,我們可以一步將輸入發布到不同的隱藏層,在層之間的移動也變得更加高效和迅速。那如何將正確的單詞和語句放到正確的位置?這時我們就用到了注意力機制。
在注意力機制里面,有一個很重要的機制就是多頭注意力機制。如果我們在多頭注意力機制下,使用Transformer,那注意力機制會將所有的輸入放在一個袋子里面,它不知道每一個單詞應該放到什么位置,所以我們需要給它們加上位置點,然后通過多頭注意力機制,將不同的信息分配到不同的位置。
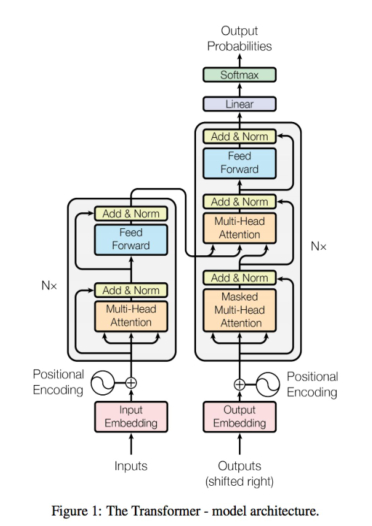
關于解碼器,首先編碼器開始生成一些數據,再加上一層解碼器輸出的內容,最后輸入到下一層,這就是翻譯的過程。所以從輸入每一個詞,然后生成下一層,這是同時進行的。在解碼方面,它也是基于上一層的工作結果來進行解碼的。觀察機器學習的一些結果,大家可以看到BLEU值不斷升高,達到了29.1,這是英語到德語的翻譯分數,人類翻譯能夠達到31分,因此模型的翻譯表現已經非常棒了。右邊是我們的訓練成本,也并沒有顯著的升高。

2018年,我們的工作重點是長文本的生成。當時我們試圖通過熱門搜索來生成整個維基百科的文章,訓練了2300萬個參數,比如“左邊標黃的這一段話事實上沒有意義,是讀不通的”,我們發現參數越多的時候它的精度會越高。
2019年,谷歌旗下另外一個模型GPT2,是主要生成語言的。當時經濟學領域一本非常有名的雜志,采訪了這個模型的創建者。有趣的是,采訪問題是人類問的,答案是機器給的。比如人類問,你認為我們人類該有多擔心計算機會取代我們的工作?計算機答,這取決于計算機將會扮演什么樣的角色。所以大家可以看到計算機是能夠回答問題的。當然,如果問題越長,它的答案也會越來越讓人無法理解,沒有任何意義,這是現在存在的一個問題。
2020年出現了GPT3,整個故事都是由機器生成。比如一個人站在門口,他想要進去,音樂突然停止了,模型說,你好。然后人類說,我現在尋找一本書。接著模型說,你為什么想要這本書。整個文章模型能夠不斷地回答人類的問題,雖然它的問題都是一句話一句話進行,但是它的邏輯是非常清楚的,它說的每一句話都是有意義的。它還能生成一些人的內心想法,能把整個故事繼續發展下去。比如它里面還談到了你走進去以后看到了一個非常漂亮的女人,她有著長長的金發,她還穿著紫色的裙子,你覺得你見過這個女人,但事實上你卻想不起來她到底是誰。這里模型不僅能生成句子,還能生成段落,而且這個故事還會不斷地繼續,無限的發展。
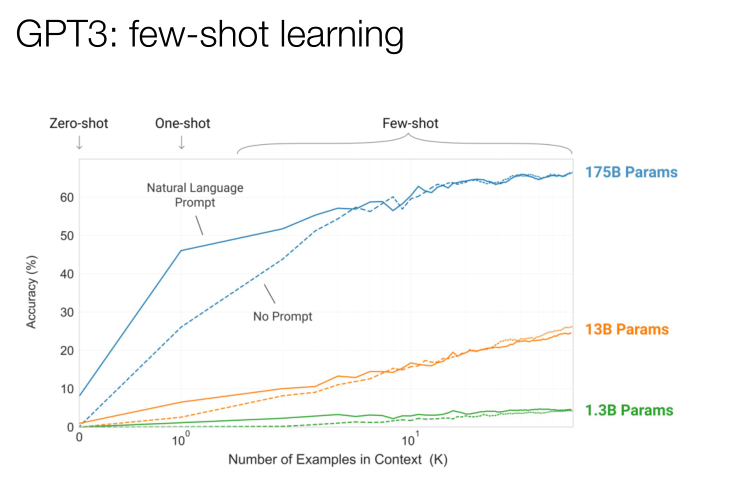
這里非常關鍵的一個模型是小樣本學習。我們可以在這里描述一個非常短的任務,這個模型并沒有預先訓練過,它是未監督的,但它仍然能將英文翻譯成法語,雖然它沒有那些監督訓練過的模型翻譯得那么好,但是它也有一定的翻譯效率。小樣本學習的效果,取決于里面的例句有多少。很有趣的事情是當模型越來越大,它的效率會越來越高,其中有一個點是激增的,也就是說它得到的提示越多,它的學習效率越高,這個發展在過去的一年是非常可喜的。
上面我跟大家談了很多的語言模型,都是我工作過的一些模型,下面也想跟大家聊一聊圖像識別。
2017年,圖像生成我們做了一些模型測試,這些圖形的清晰度并不好。2020年,DALL-E模型給它一些文字提示,它就能通過AI自動生成一些圖像。
示例:這張圖像有一個小白蘿卜,它穿著一條芭蕾舞小短裙正在溜一只狗,通過文字提示來生成圖像。

從2020年開始,谷歌同事引進了視覺Transformer,在圖像方面我們需要很多的輸入來對它進行訓練,我們需要很多預訓練的數據庫,數據子集,深度學習的這些模型不僅可以用在文本方面,也可以用在圖像等方面。
我們想要得到一個很好的Transformer,如何做這些架構呢?2016年我們還沒有辦法用到PyTorch這樣的工具,就把所有數據都放到一個框架里,2020年我們有了pytorcb,這些數據圖書館都非常有用,可以看到很多事例,它會教你如何操作,非常容易上手。
我們也希望這些模型能有更多數據來進行訓練,比如有一個數據庫Tensop tensor Trax,可以下載這些數據集并創建一個自己的數據集,也可以將自己的輸入建成一個一個輸入管道,重復以上步驟我們可以隨時下載這些輸入和輸出的結果。
有一個非常有名的資源庫叫Hugging Face。它的頁面是對話形式的,在網站上輸入你的文本,然后運行。你不需要下載任何東西,可以直接在網站上運營,它也可以實現發布。
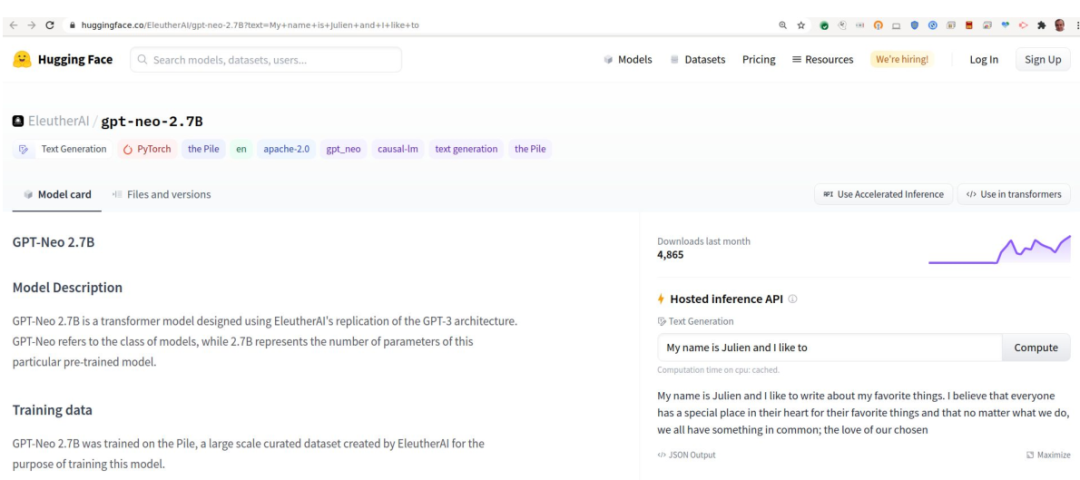
GPT neo,是一個非常高質量的反向傳播模型。這個模型很可能比GPT2的那個模型更好,大家可以看到下面寫我的名字,以及我最喜歡的事情等,如果輸入不同的參數,它會給你提供一些不同的故事。因為架構已經做好了,所以我們可以在上面運行很多個任務,像現在運行更多模型,或者創建更多的模型就越來越容易了。
未來我們將迎來一個什么樣的時代呢?我認為是多種模態的時代,一個模型不會完成所有的工作,圖像、文本、視頻、聲音等都會有不同的模型來專門處理的時代。
2017年的多模型,從輸入編碼到中間的混合,再到解碼,它們都能完成不同的任務。未來多種模態的模型將會更加廣泛的應用,將會變得更簡單更美好,結果也會被更加優化。
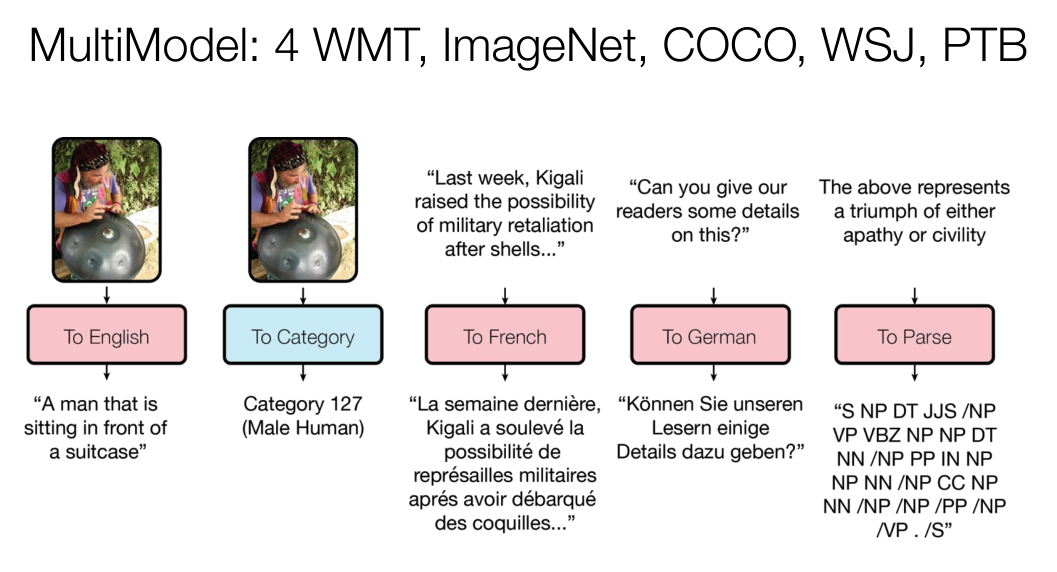
我的另一個信念是我們會有更多更好的Transformer。比如你有1000個單詞,在這個量級下,模型的運行效率是還可以的,如果是10~10萬字,問題就會變多。從右圖可以看出,這是各種各樣不同的模型在試圖解決這些問題。
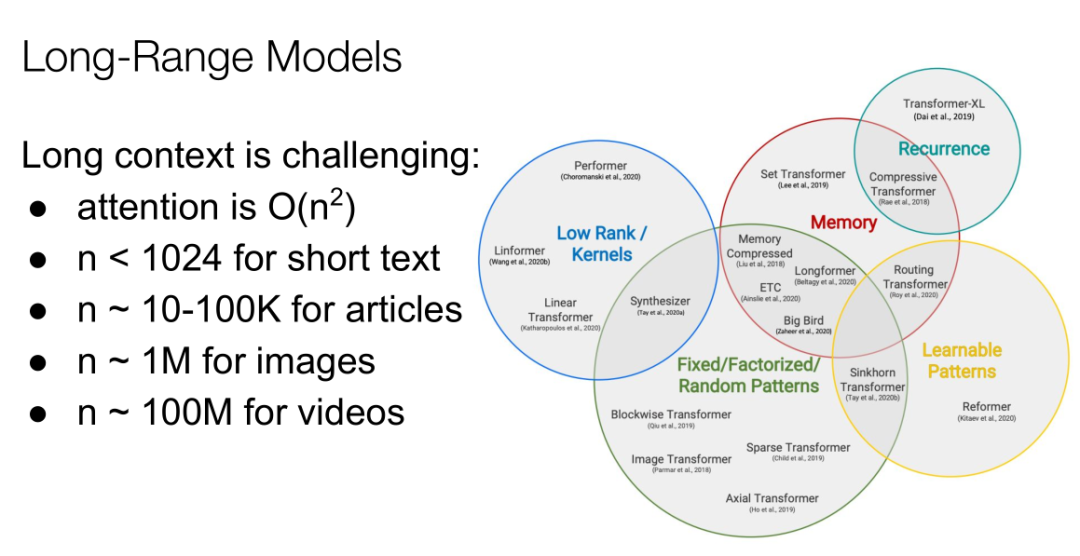
我們可以處理100萬左右的圖像,但要注意,如果一定要生成視頻,需要大概1億特殊句,因此我們有更多的工作需要做。所以趨勢是Transformer會越來越大,序列會越來越長,但我們無法將每個任務都在超級計算機上進行測試,因為需要非常強大的GPU等,同時運行速率也會越來越慢,那么解決這個問題的答案就是稀疏模型。
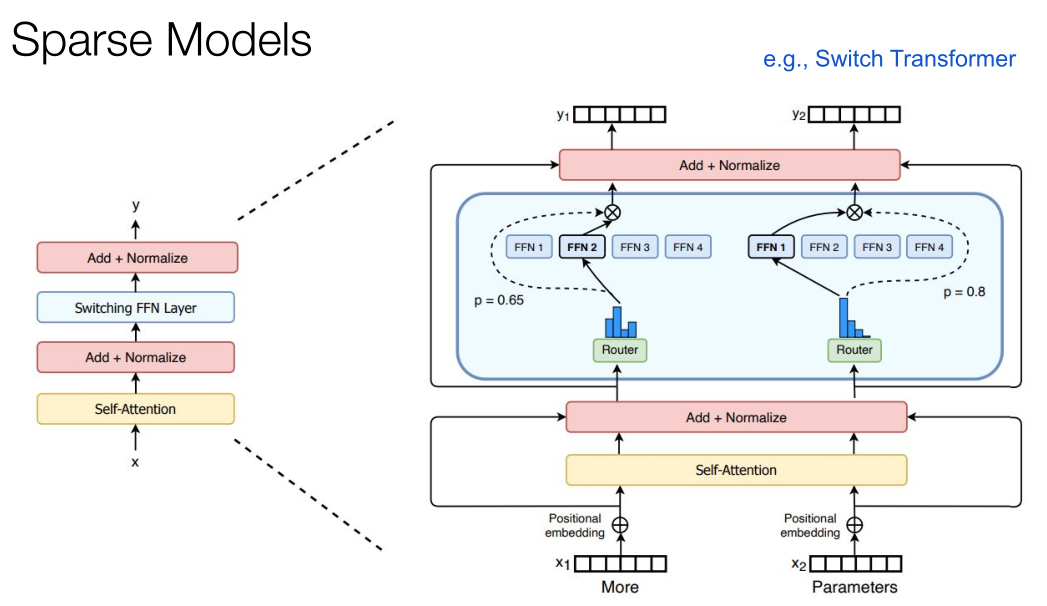
我們有很多稀疏模型可以使用,在訓練中可以將每一個字都識別出來,然后當單詞進入這個模型就會激活不同的FFN。對比一下人類大腦,它也沒有辦法隨時激活每一個神經元,那么要讓Transformer工作得越來越快,就需要建立更大的模型。因此我認為Transformer可以被作為服務來提供,它會變得更快,以數量級的方式增長,也可以處理很長的上下文。
上面跟大家展示了GPT2模型,只需要給它一些提示,它就能生成任務的答案。這是一個OPENAi的API,你只需要在上面寫上社交網絡的發言,它就能判斷出你的情緒是正面的,負面的,還是中性的。如果你有這樣一個API你需要去訓練你的模型嗎?
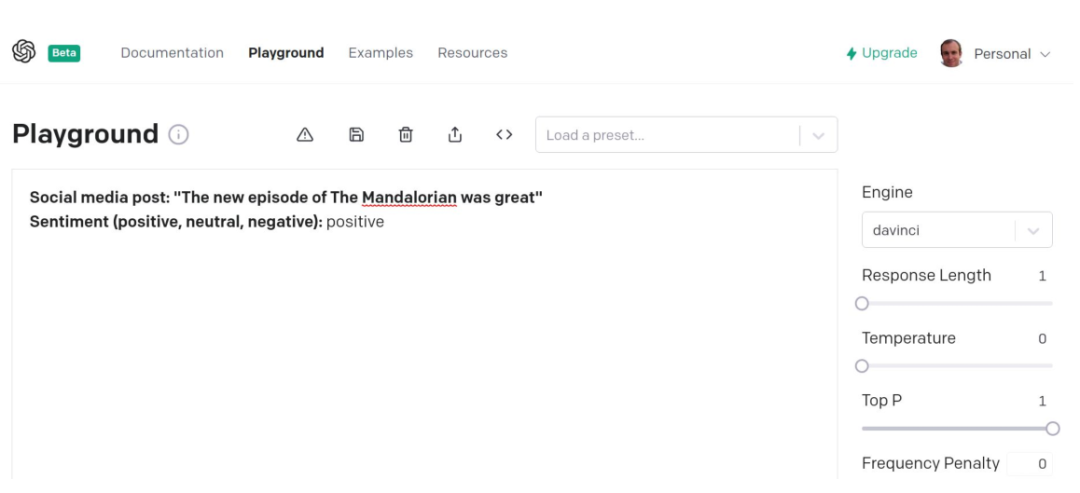
對于模型也是一樣,我認為模型將來會被作為服務來提供。當然如果你是阿里、騰訊這樣的大企業,你可能會訓練自己的模型,但它確實是需要花費很多的時間精力和成本的。未來我覺得很快我們就能夠得到,一些以服務方式提供的運行速率更快的Transformer,如果您的手里有一個快速運行的多模態Transformer能夠直接使用,您會把它來做些什么呢?
以上就是我今天想跟大家分享的內容。











