還未添加對比產(chǎn)品
登錄

暫無評分
咨詢產(chǎn)品
免費試用
基礎(chǔ)信息
產(chǎn)品介紹
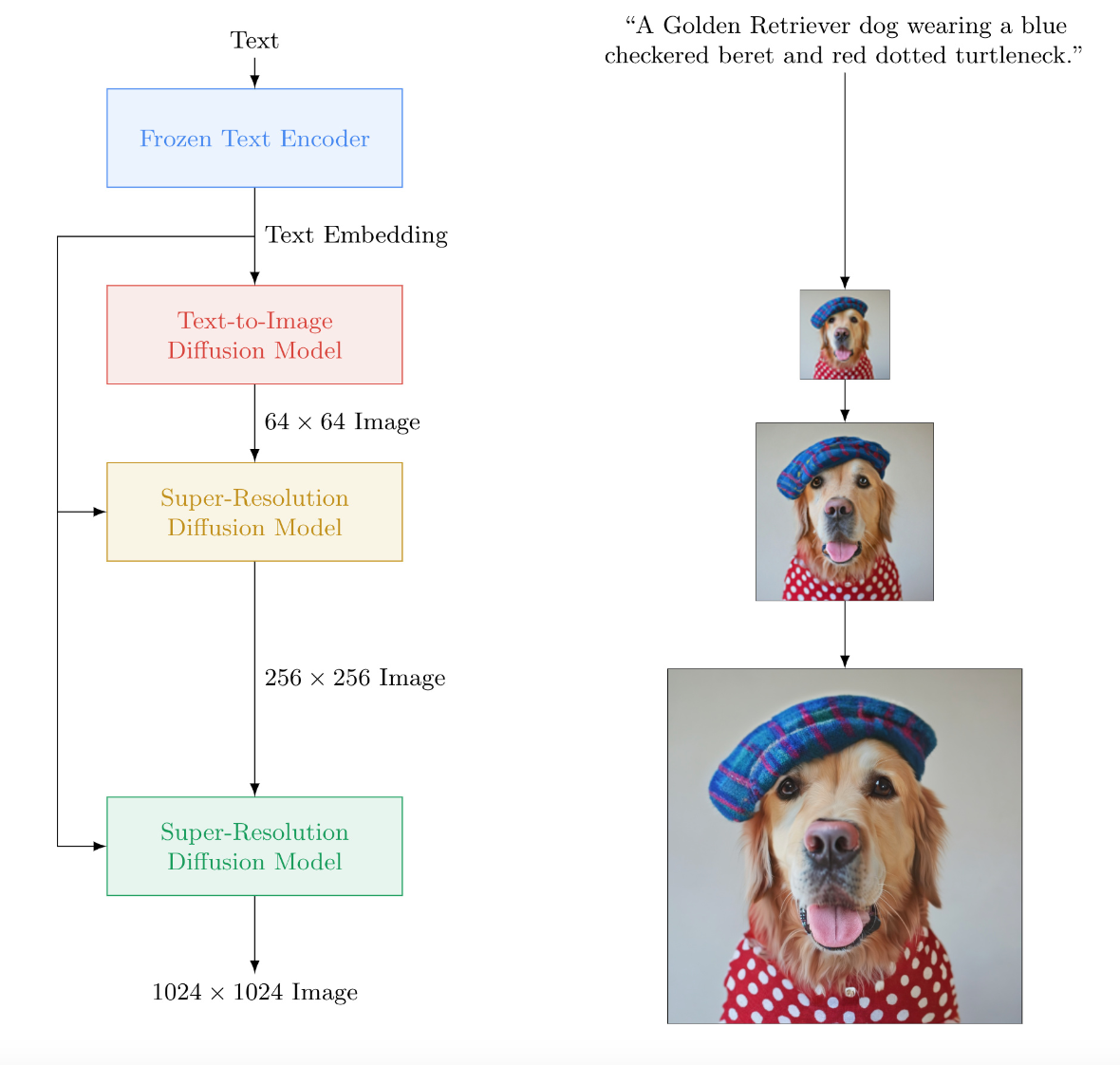
一種文本到圖像的擴散模型
Imagen,這是一種文本到圖像的擴散模型,具有前所未有的真實感和深度的語言理解。Imagen 建立在大型 Transformer 語言模型在理解文本方面的強大功能之上,并依賴于擴散模型在高保真圖像生成方面的優(yōu)勢。
我們的關(guān)鍵發(fā)現(xiàn)是,在純文本語料庫上預(yù)訓(xùn)練的通用大型語言模型(例如 T5)在為圖像合成編碼文本方面非常有效:增加 Imagen 中語言模型的大小可以大大提高樣本保真度和圖像-文本對齊不僅僅是增加圖像擴散模型的大小。
Imagen 在 COCO 數(shù)據(jù)集上獲得了 7.27 的新的最先進的 FID 分數(shù),而無需在 COCO 上進行訓(xùn)練,并且人類評估者發(fā)現(xiàn) Imagen 樣本在圖像-文本對齊方面與 COCO 數(shù)據(jù)本身相當。為了更深入地評估文本到圖像模型,我們引入了 DrawBench,這是一個用于文本到圖像模型的全面且具有挑戰(zhàn)性的基準。
使用 DrawBench,我們將 Imagen 與最近的方法(包括 VQ-GAN+CLIP、潛在擴散模型和 DALL-E 2)進行比較,發(fā)現(xiàn)人類評分者在并排比較中更喜歡 Imagen,無論是在樣本質(zhì)量方面和圖文對齊。
收起
公司名稱
Google
員工人數(shù)
- -
融資輪次
未融資
產(chǎn)品圖片


售前咨詢,預(yù)約演示,了解詳細使用場景
立即咨詢
問答
提問
暫時沒有回答
如果你對產(chǎn)品有疑問,開始 寫第一個提問
產(chǎn)品對比
消息通知
咨詢?nèi)腭v

商務(wù)合作

點評