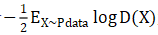gan的基本結構

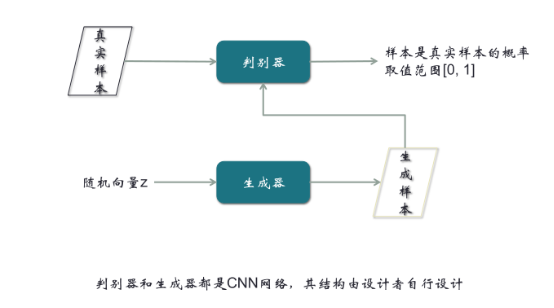
【第一步:用真實樣本訓練判別器,令它判別出1】
大家思考一下,如果我們不考慮第二步和第三步,只考慮第一步,實際上這個結構是有很大問題的。因為不管輸入的樣本是什么,想讓它輸出是1,這樣單種類的分類,沒有任何意義。一般意義上的分類器,起碼分兩類。如果不管判別器的輸入層、隱藏層、中間層是什么樣,只要最后一層保證輸出是標量1,這個很容易做到。所以這個模型,只在我們接下來的所有步驟中有意義,單獨看沒有意義,這個大家要能看出來。

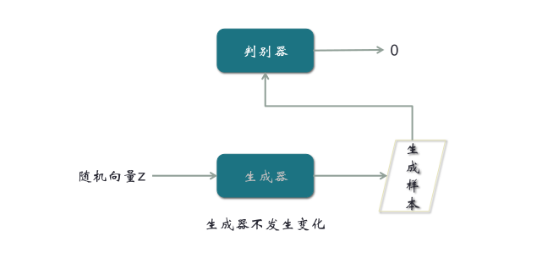
【第二步,由隨機向量經過生成器,輸出生成樣本,然后把生成樣本輸入到判別器,令它能輸出0】
與第一步聯系,就會有兩個分類,一個是1,一個是0。有了兩個分類,判別器就可以得到優化。這是我們設計這個網絡模型的結構時一定要注意的地方。在第二步,我們期望結果是0,但可能不是,就會產生誤差,從而產生梯度,產生梯度后我們沿著箭頭的反方向走,這就是反向傳播。在反向傳播過程中,可以把遇到的任何一個參數進行優化。優化過程中,有一個小技巧,在生成器的地方,把梯度截斷,不優化生成器。因為對生成器優化,最終的結果不過是輸出一個0,這不是生成器的目標。生成器的目標是生成一個很像真實樣本的假樣本。所以需要在這里截斷梯度。第二步所進行的優化,是對判別器進行的優化。結合第一步,兩步可以合成一步。
【第三步,輸入隨機向量,經過生成器輸出生成樣本,再經過判別器,輸出判別系數,這時我們期望輸出是1】
前面輸出0,我們希望用梯度優化判別器,現在用一個不同的期望輸出,來優化生成器。梯度在跑的過程中,雖然的確先經過判別器,但是因為判別器前面只對輸出樣本,期望輸出是0,現在期望輸出是1,所以梯度會路過判別器,只對生成器進行優化。所以最優化的結果,就是判別器對真實樣本總是匯報1,對生成的假樣本總是匯報0,同時我們生成器輸出的生成樣本,總是能通過判別器的判別。
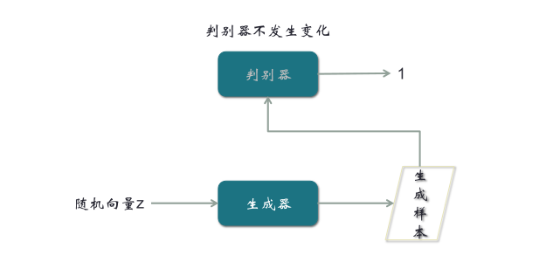
但是這里有一個矛盾的地方,生成樣本經過判別器,如果判別結果是1,會被當成真實樣本,這意味判別器的判別是錯誤的;如果判別結果趨近于0,說明判別器的判別是正確的,但是這又意味著生成器生成的結果是不理想的。這個矛盾的對抗結果,使得整個GAN的訓練非常麻煩。
二、GAN的損失函數
對判別器的訓練: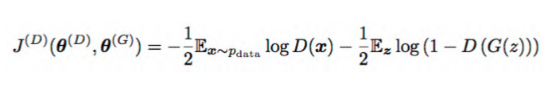
data指真實樣本,D指判別器,G指生成器。我們期望D(X)趨近于1,整個![]() 趨近于0。D(G(z))是生成器對輸入向量Z生成的樣本,作為判別器的輸入,我們期望這部分的輸入趨近于0。
趨近于0。D(G(z))是生成器對輸入向量Z生成的樣本,作為判別器的輸入,我們期望這部分的輸入趨近于0。
對生成器的訓練:
這里D(G(z))與上面相反,我們期望輸出結果是1。
(本文來源于:Boolan首席AI咨詢師—方林老師)
[免責聲明]
文章標題: gan的基本結構
文章內容為網站編輯整理發布,僅供學習與參考,不代表本網站贊同其觀點和對其真實性負責。如涉及作品內容、版權和其它問題,請及時溝通。發送郵件至36dianping@36kr.com,我們會在3個工作日內處理。